Data quality is not a random activity in the organization, even if it appears so. It might be done by an intern in Excel or by an artificial intelligence solution, it still follows a predictable pattern which we distilled in a clear process.
The six stages
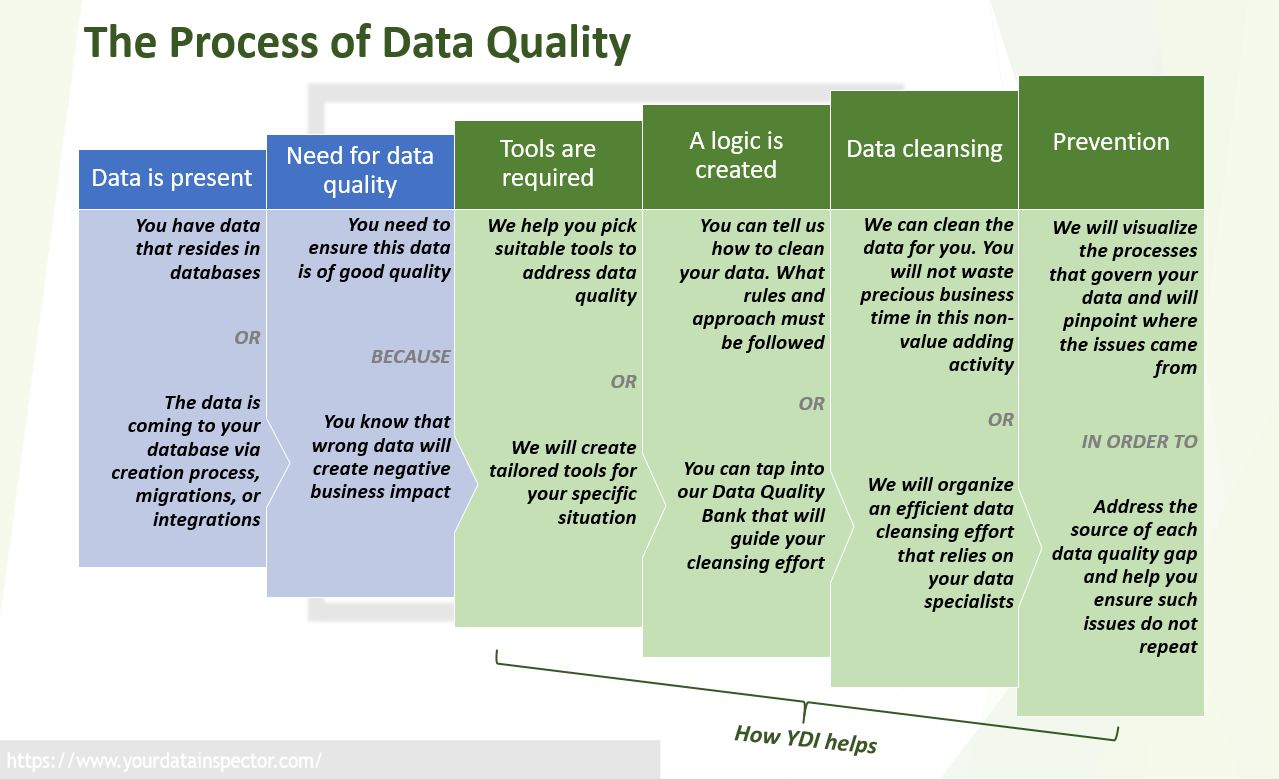
We have identified six consecutive stages that most of the data quality efforts go through. These are: (1) Data is present; (2) Need for data quality; (3) Tools are required; (4) A logic is created; (5) Data cleansing; (6) Prevention. We will unpack each one of them.
(1) Data is present
It is quite simple at first glance. Data quality is not required without data. Obviously! But the story doesn’t stop here. Usually, this data is already (or will be) used to support a business process, trigger change, research a topic etc. In other words, the data is already perceived valuable and is expected to bring benefits. An example of such data is the chamber of commerce registration of a company. This is usually a number and every business has once. Of course, not every such number is valuable. But if this company is your supplier, its specific registration number is important to you.
(2) Need for data quality
So, you have the chamber of commerce number of your supplier stored in a database. You want to use it to draft a contract but you also know that if it is wrong, there could be negative impact that you wish to avoid. Therefore, you ask an intern to check it up. It is easy with one, but what happens when there are ten thousand? Then, you have the need for data quality, not for one data point but for a whole database.
(3) Tools are required – YDI helps you select the most suitable one
If we assume the intern needs around five minutes to find and correct one faulty record (including the manual identification of the record in the database, searching for the correct value, modifying and recording it), the total duration to check and fix ten thousand records is more than one hundred business days. This quickly becomes impractical. When you need to check a whole database and correct the wrong records, more sophisticated tools are required.
There are plenty of those available, but from a business perspective, you need to find the balance between impact and cost. Yes, you can implement the most state-of-the-art cloud based artificial intelligence to check and fix your data but if you have only ten thousand records, this is maybe an overkill. With this volume, Microsoft Excel might be pretty sufficient.
We, in YDI, assess your situation and help you select those tools that are the most suitable for you. In fact, we try reusing your existing ones as our default approach. We will suggest investing in a new solution only if there is no other viable choice. We are not vendors for tools, we just want to find the faulty data and fix it in the easiest and most convenient way possible.
(4) A logic is created – Our off-the-shelf Data Quality Bank already has hundreds of checks
You have selected the most appropriate tool. Now, someone has to define what this tool does. Smarter logic you create, more data gaps will be discovered and cleaned. Here comes an uncomfortable question. Do you have the knowledge to develop this logic?
This exact question made us start YDI. When not addressed properly, the data quality effort will be either incomplete, superficial or too expensive. So, at the heart of our proposition we created our “Data Quality Bank”. This is a collection of data quality checks that we can apply to any tool. So, instead of investing time in research and development, you can tap into our Data Quality Bank for the best set of checks that you will need for your specific data. It is almost plug and play.
(5) Data cleansing – we will clean automatically; we will guide you for the rest
Once the tool checks the real data, chances are that data gaps will appear. It is possible that some surprises will pop up too. What then? How should you address the task of cleaning them? Should you jump into manual data cleansing? How long it will take? Should you correct at all? Are there alternatives that are easier, cheaper and more accessible?
YDI addresses all these questions in a stage that we call “FIX”. Data cleansing can become daunting task especially when you are looking at a mountain of issues for the first time. We help you conquer this mountain. We will try to fix as many of your issues automatically, using another set of dedicated algorithms we created. For those gaps that cannot be fixed automatically, yes there could be such, we know how to organize efficient processes that address them limiting your effort as much as possible. Or if you do not want to spend precious business time in such non-value adding tasks, we will manually clean this data for you.
(6) Prevention – Once fixed, YDI will not let the issues come back
Data deteriorates over time. With different rate for different types of data, but it does. So, once you have fixed the faulty data, if nothing changes, there will not be long before the issues come back. The best is to set yourself up in such a way, so that those gaps, once fixed, never come back.
This is how we finish one standard data quality projects. We work with your teams to ensure that all sources of data quality issues are addressed and no known problems come back. We guide you to establish system validations to prevent faulty data coming in, we set up systems to monitor the health of your data and report gaps. We will establish processes and will train your people to know what to do when anomalies start appearing. All with the purpose of having data that sustainably delivers value to you and does not interrupt your business.